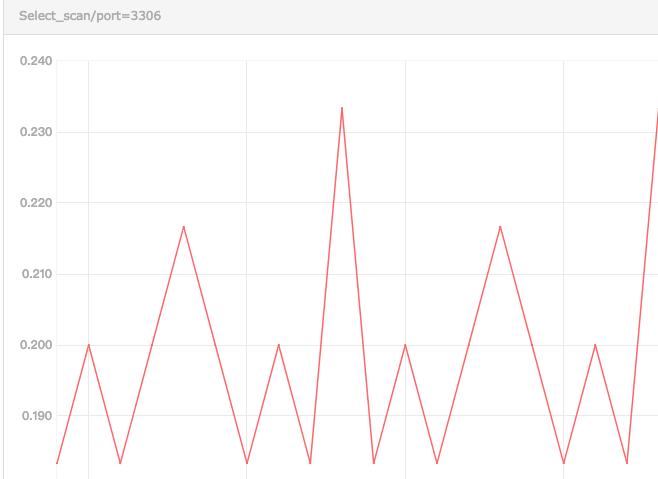
今天在整理mysql监控项数据时,发现对于全表扫描select_scan这个指标,监控到的数据竟然有的时候是小数,如图1所示。
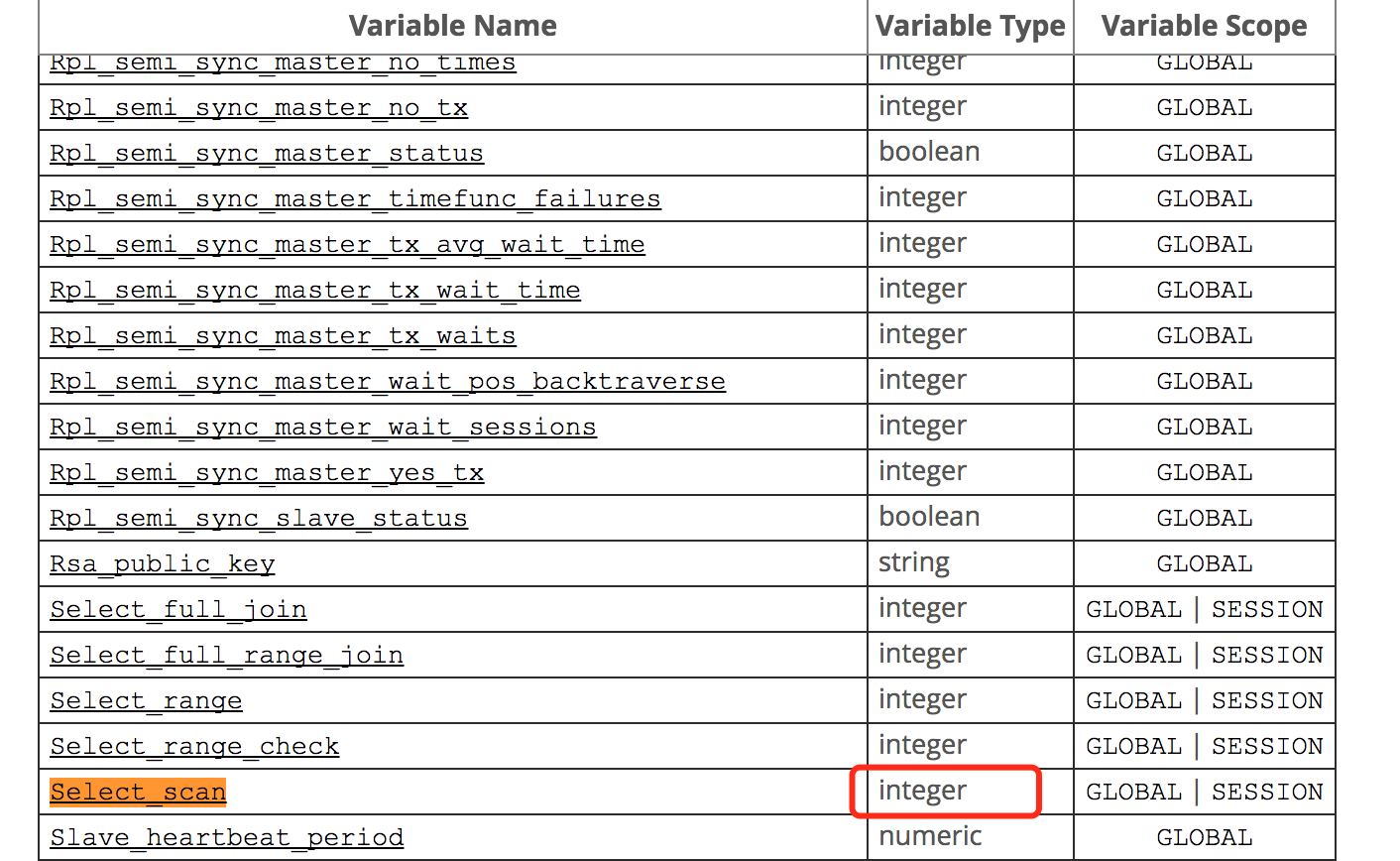
但是按理说次数应该是整数呀,并且在mysql官方文档中,也明确说明是integer类型,如图2所示。
于是我开始怀疑这个上报指标是不是有问题,并且群里之前有人吐槽mysql的插件mymon的好多监控指标有问题,单位模糊之类。所以我开始从mymon入手,调查这个metric的值的获取是否正确。
今天在整理mysql监控项数据时,发现对于全表扫描select_scan这个指标,监控到的数据竟然有的时候是小数,如图1所示。
但是按理说次数应该是整数呀,并且在mysql官方文档中,也明确说明是integer类型,如图2所示。
于是我开始怀疑这个上报指标是不是有问题,并且群里之前有人吐槽mysql的插件mymon的好多监控指标有问题,单位模糊之类。所以我开始从mymon入手,调查这个metric的值的获取是否正确。
在transfer组件的配置文件中有三个监听模块,分别是:http监听6060,rpc监听8433,socket监听4444。其中http为组件提供对外的控制接口;rpc为agent提供上报服务;socket提供一种基于socket的连接方式,但不推荐使用,日后可能会被废弃。
经transfer组件后,由agent上报来的数据,会通过一致性hash路由到judge和graph组件。
通过进程内队列将收集的数据放进queue,再由send_tasks,批量pop出batch条记录进行发送。
var (
TsdbQueue *nlist.SafeListLimited
JudgeQueues = make(map[string]*nlist.SafeListLimited)// make用来初始化
GraphQueues = make(map[string]*nlist.SafeListLimited)// map后面的string是key type, 后面的指针是value type
)
judge和graph发送逻辑类似,发送过程使用简单for循环进行重试,最多重试三次。
https://github.com/ZhuoRoger/redismon
https://github.com/iambocai/falcon-monit-scripts/tree/master/redis
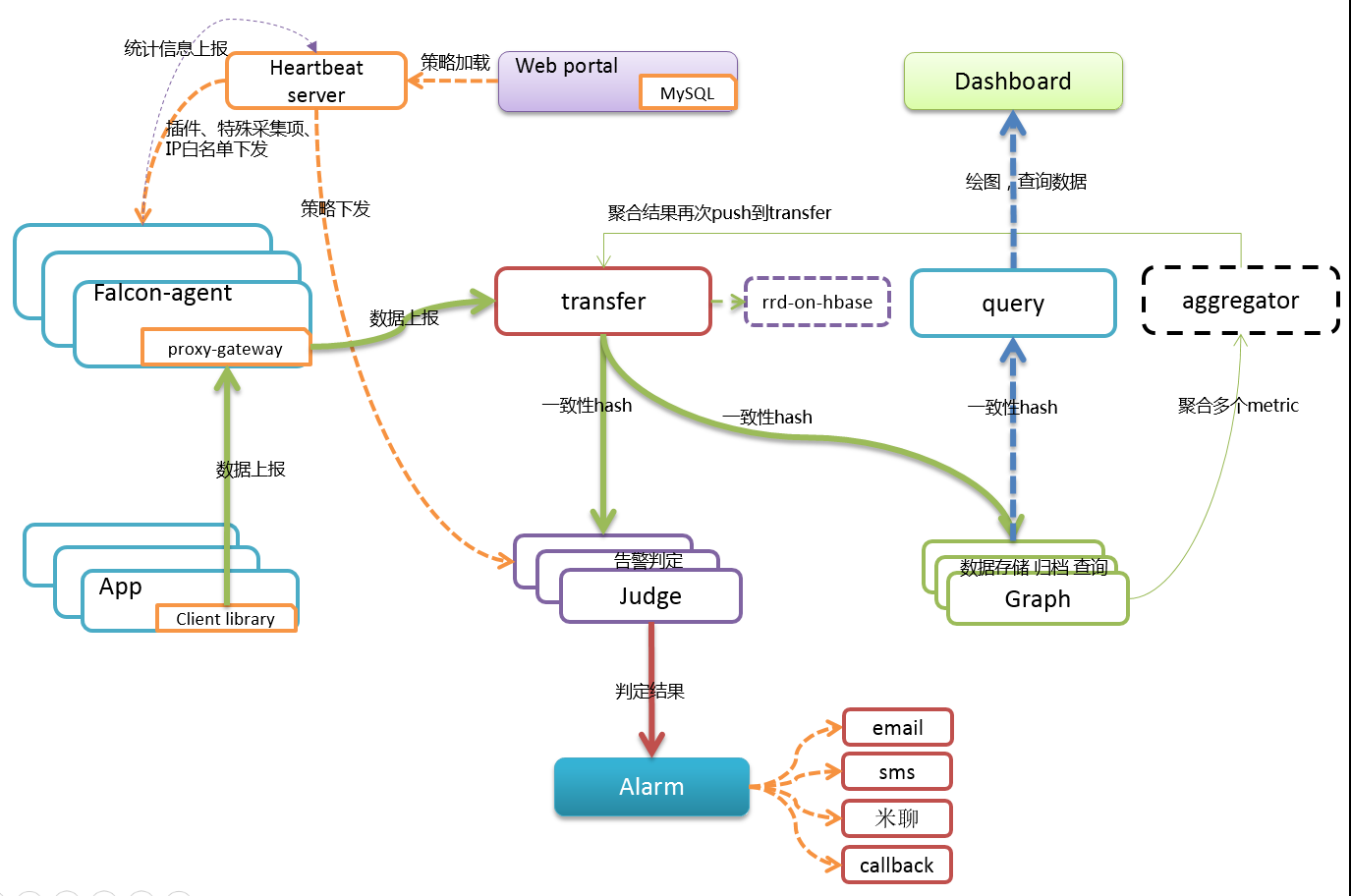
agent包含两部分上报信息:其一是上报心跳到HBS,其二是上报metrics到transfer。
main.go在根目录下,是程序的入口。主函数依次创建一系列协程。除了在main中显示通过go创建的外,其他均在cron包中创建。
funcs.BuildMappers()函数,创建Mappers,包含四个FuncsAndInterval机器负载信息、硬件信息、服务器监控信息、开源软件监控指标。即Mappers中已经规定包含四个FuncsAndInterval,每个FuncsAndInterval中有一个Fs,Fs是一个model.MetricValue结构体数组指针,四个Fs内容如下:
a、AgentMetrics,CpuMetrics,NetMetrics,KernelMetrics,LoadAvgMetrics,MemMetrics,DiskIOMetrics,IOStatsMetrics,NetstatMetrics,ProcMetrics,UdpMetrics
b、DeviceMetrics
c、PortMetrics,SocketStatSummaryMetrics
d、DuMetrics
Metrics主要有两种类型,GAUGE和COUNTER,前者为瞬时指标,后者为累加数据。
#包
每个 Go 程序都是由包组成的。
程序运行的入口是包 main 。
这个程序使用并导入了包 “fmt” 和 “math/rand” 。
按照惯例,包名与导入路径的最后一个目录一致。例如,”math/rand” 包由 package rand 语句开始。
#并发
##goroutine
goroutine 是由 Go 运行时环境管理的轻量级线程。
go f(x, y, z)
开启一个新的 goroutine 执行
f(x, y, z)
f,x,y 和 z 是当前 goroutine 中定义的,但是在新的 goroutine 中运行 f。
goroutine 在相同的地址空间中运行,因此访问共享内存必须进行同步。
package main
import (
"fmt"
"time"
)
func say(s string) {
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Println(s)
}
}
func main() {
go say("world")
say("hello")
}
当前线程执行字节码的行号指示器。在虚拟机的概念模型里,通过这个行号指示下一条要执行的指令,分支、循环、跳转、异常处理、线程恢复等。线程独立。当执行java方法的时候,指示的是虚拟机字节码指令的地址;执行native方法是,这个值为空。
唯一一个没有在虚拟机规范中规定任何OutOfMemoryError的区域。
线程私有。栈帧的入栈和出栈过程。每个栈帧存储局部变量表、操作数栈、动态链接库、方法出口等信息。可以抛出StackOverflowError异常,栈本身不够用;OutOfMemoryError,扩充栈的时候没有申请到足够的空间。
运行native方法服务。也会抛出上述两个异常。
虚拟机管理的最大一块内存。虚拟机规范要求,所有对象实例以及数组都要在堆上分配。分代:新生代和老年代;新生代分为Eden区和两个Survivor区。规范规定,堆可以处于物理上不连续的内存空间中,只要逻辑上连续即可,就像磁盘一样。当堆中没有足够的内存分配,且堆无法扩展的时候,将会跑出OutOfMemoryError异常。
线程共享,存储被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。HotSpot将其称为永久代,是因为GC分代收集扩展至方法区。回收目标针对常量池的回收和类型的卸载。也会跑出OutOfMemoryError异常。
方法区的一部分,存放各种字面量和符号引用。String类的intern()返回这里的值。同意可能返回OutOfMemoryError异常。
Direct Memory并不是虚机运行时数据区的一部分,也不是虚拟机规范定义的内存区域。堆内的DirectByteBuffer对象对堆外内存引用进行操作,避免在java堆和native堆间来回复制数据,一些场景可以提高性能。
对象类型信息存储在方法区。
栈和堆之间的访问方式一般两种:1.使用句柄,reference中存储的是稳定的句柄地址,对象移动时只会改变句柄中的实例数据指针;2.使用之间指针,节省一次指针寻址。
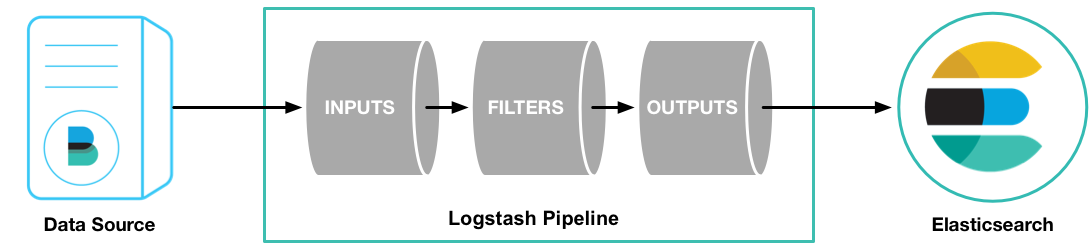
Logstash is a tool for managing events and logs. You can use it to collect logs, parse them, and store them for later use (like, for searching).
什么是 Logstash?为什么要用 Logstash?怎么用 Logstash?
安装
使用软件仓库的配置
rpm –import http://packages.elasticsearch.org/GPG-KEY-elasticsearch
cat > /etc/yum.repos.d/logstash.repo <<EOF
[logstash-5.0]
name=logstash repository for 5.0.x packages
baseurl=http://packages.elasticsearch.org/logstash/5.0/centos
gpgcheck=1
gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch
enabled=1
EOF
yum clean all
yum install logstash
可以访问 https://www.elastic.co/downloads/logstash 页面找对应操作系统和版本
运行
bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
结果
{
"message" => "Hello World",
"@version" => "1",
"@timestamp" => "2014-08-07T10:30:59.937Z",
"host" => "raochenlindeMacBook-Air.local",
}
plugin
Usage:
bin/plugin [OPTIONS] SUBCOMMAND [ARG] ...
Parameters:
SUBCOMMAND subcommand
[ARG] ... subcommand arguments
Subcommands:
install Install a plugin
uninstall Uninstall a plugin
update Install a plugin
list List all installed plugins
Options:
-h, --help print help
Filebeat client可以在服务端收集log文件,并传送到logstash实例。
keys *
exists key
del key 由于del不支持通配符,所以可以结合管道和xargs,redis-cli keys "user:*" | xargs redis-cli del
type key 获取键值的数据类型
set key value 赋值
get key 取值
incr key 递增数字
incrby key increment 增加指定整数
decr key
decrby key decrement
incrbyfloat key increment
append key value 向尾部追加
strlen key 获取字符串长度
mget key [key ...] 同时获取多个键值
mset key value [key value ...] 同时设置多个键值
最好使用“对象类型:对象ID:对象属性”来命名一个键,eg,user:1:friends
hset
hget
hmset
hmget
hgetall
hexists
hsetnx key field value 如果字段存在命令不执行任何操作
hincrby key field increment
hdel key field [field ...]
hkeys key 获取key对应的所有字段
hvals key 获取key对应的所有字段对应的值
hlen key 获取字段数量
list可以向两端添加元素,或者获得列表的某一片段
lpush key value [value ...]
rpush key value [value ...]
lpop key
rpop key
llen key
lrange key start stop
lrem key count value
lindex key index
lset key index value
ltrim key start end
linsert key before|after pivot value
rpoplpush source destination
sadd key number [number ...]
srem key number [number ...]
smembers key
sismember key member
sdiff key [key ...]
sinter key [key ...]
sunion key [key ...]
zadd key score member [member ...]
zscore key member
zrange key star stop [withscores] 按分数从小到大
zrevrange key start stop [withscores]
zrangebyscore key min max [withscores] [limit offset count]
zincrby key increment member
zcard key 获取集合中元素的数量
zcount key min max
zrem key member [member ...]
zremrangebyrank key start stop 按排名范围删除元素
zremrangebyscore key min max 按照分数范围删除元素
zrank key member 获取元素排名
zrevrank key member
multi
...
exec
watch
在关系型数据库中一般需要一个额外的字段记录到期时间,然后定期检查,删除过期数据。在redis中可以使用expire命令设置一个键的过期时间,到时间后redis会自动删除它。
set key value
expire key time 设置过期时间,返回1表示成功;0表示键不存在或设置失败
ttl key 返回键的剩余时间,单位是秒。当键不存在时,返回-2。-1表示永久键。
persist key 取消过期时间,将键改为永久键。使用set和getset赋值的同时也可以清楚过期时间。
对应的还有另外一组设置毫秒时间的
pexpire
pttl
过期时间实现访问频率限制
过期时间实现缓存。限制redis占用的最大内存,不设置过期时间,而让redis通过一定的规则淘汰不需要的缓存键。修改maxmemory参数,设置maxmemory-policy。eg. allkeys-lru
127.0.0.1:6379> sadd posts 2 6 12 26
(integer) 4
127.0.0.1:6379> smember posts
(error) ERR unknown command 'smember'
127.0.0.1:6379> smembers posts
1) "2"
2) "6"
3) "12"
4) "26"
127.0.0.1:6379> hset post:2 time 1352619200
(integer) 1
127.0.0.1:6379> hset post:6 time 1352619600
(integer) 1
127.0.0.1:6379> hset post:12 time 1352610100
(integer) 1
127.0.0.1:6379> hset post:26 time 1352612000
(integer) 1
127.0.0.1:6379> sort posts
1) "2"
2) "6"
3) "12"
4) "26"
## 这里by的感觉很像是表连接
127.0.0.1:6379> sort posts by post:*->time desc
1) "6"
2) "2"
3) "26"
4) "12"
通过sort命令的get参数,该参数不影响排序,作用是似的sort命令的返回结果不再是元素自身的值,而是get参数中指定的键值。
127.0.0.1:6379> sort posts by post:*->time desc get post:*->title
1) "66666"
2) "windows 8"
3) "262626"
4) "121212"
## 一个sort也可以带有多个get参数(但by只能有一个)
sort posts by post:*->time desc get post:*->title get post:*->time get #
1) "66666"
2) "1352619600"
3) "windows 8"
4) "1352619200"
5) "262626"
6) "1352612000"
7) "121212"
8) "1352610100"
get # 会返回元素本身。
store参数保存排序结果
sort posts by post:*->time desc get post:*->title get post:*->time get # store sort.result
(integer) 12 ## 保存的键类型是列表类型,返回值为结果个数
127.0.0.1:6379> lrange sort.result 0 -1
1) "66666"
2) "1352619600"
3) "6"
4) "windows 8"
5) "1352619200"
6) "2"
7) "262626"
8) "1352612000"
9) "26"
10) "121212"
11) "1352610100"
12) "12"
sort对性能的影响
O(n+mlog(m)),n为待排序列表中元素个数,m为排序结果返回的个数。
订阅功能,将用户邮箱存储在集合中,当新增文章后,就向集合中的邮箱地址发送通知邮件。
当页面需要进行如发送邮件、复杂数据运算等耗时较长的操作时会阻塞页面的渲染,为了避免用户等待太久,应该使用独立的线程来完成。
松耦合,生产者和消费者无需知道彼此的实现细节。易于扩展,消费者可以有多个,分布在不同机器中,轻松降低单台服务器的负载。
结合lpush和rpop,往列表左侧添加,右侧取出,模拟消息队列。同时redis提供brpop命令,当没有元素可以取出时,brpop命令将会阻塞,直到油新元素加入。
brpop key timeout
其中time为超时时间,0表示不限制等待时间,即将一直等待下去。
brpop key [key ...] timeout 可以实现优先队列,当多个key对应的列表都有数据可以取出的时候,按从左到右的列表顺序
当一组命令中每条命令都不依赖于之前命令的执行结果时就可以将这组命令一起通过管道发出,从简降低往返时延累计值。
通过快照(snapshotting)完成,当出现以下几种情况时,进行快照:
默认快照文件存储在redis当前进程的工作目录中的dump.rdb文件中,通过redis-cli启动客户端时,文件在redis-cli所在的文件夹中。
使用fork函数赋值一份当前进程(父进程)的副本(子进程)。父进程继续接受并处理客户端的请求,而子进程开始将内存中的数据写入硬盘中的临时文件。写入所有数据后会用改临时文件替换旧的RDB文件,至此完成一次快照操作。
fork的时候,会使用写时赋值策略(copy-on-write),开始时共享内存,当父进程需要更改数据时,操作系统会将该数据复制一份保证子进程的数据不受影响,所以RDB文件存储的是执行fork时刻的内存数据。
append only file,默认情况下不开启,可通过appendonly yes参数启用。每执行一条会更改redis数据的命令,redis就会将该命令写入磁盘中的aof文件。aof文件的位置和rdb文件的位置相同。
以纯文本形式记录了redis执行的写命令。每当达到一定条件时redis就会自动重写aof文件,去除文件中冗余的数据。
由于操作系统缓存机制,数据并没有真正地写入硬盘,而是进入系统的硬盘缓存。默认情况下每30s执行一次同步操作,将缓存中的内容真正写入硬盘。
appendfsync always 每次操作都同步
appendfsync everysec 没个若干秒同步;这是兼顾性能和安全的考虑。
appendfsync no 不同步,由操作系统决定,即30s
curl -XPUT http://localhost:9200/blog/article/1 -d '{
"title": "New version of es!",
"content": "...",
"tags": [
"announce",
"es",
"release"
]
}'
当然也可以通过如下命令创建
curl -XPUT http://localhost:9200/blog/
当索引存在的时候,结果会提示
{
"error": {
"root_cause": [
{
"type": "index_already_exists_exception",
"reason": "index [blog/mwdQFFt9QTydOWX2V_0d8Q] already exists",
"index_uuid": "mwdQFFt9QTydOWX2V_0d8Q",
"index": "blog"
}
],
"type": "index_already_exists_exception",
"reason": "index [blog/mwdQFFt9QTydOWX2V_0d8Q] already exists",
"index_uuid": "mwdQFFt9QTydOWX2V_0d8Q",
"index": "blog"
},
"status": 400
}
es的结果也是以json显示的,相关字段会有提示index already exists
在创建第一个文档的时候可能并不关心索引,如果索引blog不存在,es会默认自动创建该索引。
action.auto_create_index: -an*, +a*, -*
可以配置是否自动创建索引,eg,对于a开头的自动创建,an开头的不创建,其他索引也必须手动创建。
在创建索引的时候,可以通过settings指定相关参数,如
"settings": {
"number_of_shards":
"number_of_replicas":
}
curl -XDELETE http://10.10.193.203:9200/blog2/
es对索引字段的类型存在自动检测,同时会对索引中未包含的字段自动加入到索引字段中,有时候这样是我们不想看到的。可以通过”dynamic”:”false”来关闭自动添加字段。
es中使用模式映射(schema mapping)定义索引结构。
PUT twitter/tweet/1
{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
# 修改某一版本文档
PUT twitter/tweet/1?version=1
{
"message" : "elasticsearch now has versioning support, double cool!"
}
接受op_type参数,以下两者等价。
PUT twitter/tweet/1?op_type=create
{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
PUT twitter/tweet/1/_create
{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
当不传入id时,默认生成id,并索引文档
POST twitter/tweet/
{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
可以通过routing参数,设置路由,这样,可以让多个文档路由到相同的分片;依次,查询时也要设置路由参数,否则无法查询到。Note, issuing a get without the correct routing, will cause the document not to be fetched.
获取文档get
GET /twitter/tweet/1
curl -XGET "http://10.10.193.203:9200/twitter/tweet/1"
get默认会返回文档的source字段,除非增加参数_source=false
curl -XGET 'http://localhost:9200/twitter/tweet/1?_source=false'
从source字段中包含或删除
GET /twitter/tweet/2?_source_include=user&_source_exclude=message
GET /twitter/tweet/2?_source_include=user,message
Stored Field
PUT twitter
{
"mappings": {
"tweet": {
"properties": {
"counter": {
"type": "integer",
"store": false #不存储类型
},
"tags": {
"type": "keyword",
"store": true #存储类型
}
}
}
}
}
PUT twitter/tweet/1 #索引一个文档
{
"counter" : 1,
"tags" : ["red"]
}
GET twitter/tweet/1?stored_fields=tags,counter #查询两个存储字段
# 结果只有tags字段返回,非stored字段将被查询忽略
{
"_index": "twitter",
"_type": "tweet",
"_id": "1",
"_version": 1,
"found": true,
"fields": {
"tags": [
"red"
]
}
}
通过/{index}/{type}/{id}/_source直接获取source字段
GET /twitter/tweet/2/_source
# 也可以增加参数
GET /twitter/tweet/2/_source?_source_include=*.id&_source_exclude=entities'
curl -XDELETE 'http://localhost:9200/twitter/tweet/1'
DELETE /twitter/tweet/1
同样受routing参数影响
PUT test/type1/1
{
"counter" : 1,
"tags" : ["red"]
}
POST test/type1/1/_update
{
"script" : {
"inline": "ctx._source.counter += params.count",
"lang": "painless",
"params" : {
"count" : 4
}
}
}
结果
{
"_index": "test",
"_type": "type1",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"counter": 5,
"tags": [
"red"
]
}
}
POST test/type1/1/_update
{
"script" : {
"inline": "ctx._source.tags.add(params.tag)",
"lang": "painless",
"params" : {
"tag" : "blue"
}
}
}
结果
{
"_index": "test",
"_type": "type1",
"_id": "1",
"_version": 3,
"found": true,
"_source": {
"counter": 5,
"tags": [
"red",
"blue"
]
}
}
增加新字段
POST test/type1/1/_update
{
"script" : "ctx._source.new_field = \"value_of_new_field\""
}
删除字段
POST test/type1/1/_update
{
"script" : "ctx._source.remove(\"new_field\")"
}
将doc参数merge到文档1中
POST test/type1/1/_update
{
"doc" : {
"name" : "new_name"
}
}
如果更新的文档不存在,可以插入
POST test/type1/1/_update
{
"doc" : {
"name" : "new_name"
},
"doc_as_upsert" : true
}
mget
GET /_mget
{
"docs" : [
{
"_index" : "test",
"_type" : "type1",
"_id" : "1"
},
{
"_index" : "test",
"_type" : "type1",
"_id" : "2"
}
]
}
合并index参数
curl 'localhost:9200/test/_mget' -d '{
"docs" : [
{
"_type" : "type1",
"_id" : "1"
},
{
"_type" : "type1",
"_id" : "2"
}
]
}'
合并type参数
curl 'localhost:9200/test/type1/_mget' -d '{
"docs" : [
{
"_id" : "1"
},
{
"_id" : "2"
}
]
}'
合并id参数
curl 'localhost:9200/test/type/_mget' -d '{
"ids" : ["1", "2"]
}'
当type参数为空,或者设置为_all的时候,将会返回满足id的第一条文档记录
mget和get类似,也可以设置_source字段的过滤
GET /_mget
{
"docs" : [
{
"_index" : "test",
"_type" : "type1",
"_id" : "1",
"_source" : true
},
{
"_index" : "test",
"_type" : "type1",
"_id" : "1",
"_source" : ["tags", "counter"]
},
{
"_index" : "test",
"_type" : "type1",
"_id" : "1",
"_source" : {
"include": ["tags"],
"exclude": ["name"]
}
}
]
}
query_string
GET bank/account/_search
{
"query":{
"query_string":{"query":"state:PA"}
}
}
在上述DSL中增加
"from": 1
, "size": 3
es5之前的版本stored_fields就叫做fields。如果未指定stored_fields,返回结果将返回_source字段。
"stored_fields":["account_number", "age", "state"]
GET bank/account/_search
{
"query": {
"match_all": {}
}
}
在查询字符串执行操作前需要分析。
只针对倒排索引中的确切词(term)进行操作。经常被用在结构化数据结构,包括数字、日期、枚举等。
包含改词条的文档,确切的、未经分析的词条。这里的包含,对于英文来说是空格分隔的自然词。address字段,包含avenue的。avenue在建立索引的时候已经变成了小写。
GET bank/account/_search
{
"query": {
"term": {
"address": "avenue"
}
}
}
Java API
QueryBuilder qb = termQuery(
"address",
"avenue"
);
在term中可以增加boost,调节权重。在此例子中由于参与搜索的只有address一个匹配字段,所以跳转address的权重为10,相当于调整得分为原来的10倍。
"term": {
"address": {
"value": "avenue",
"boost": 10
}
}
在5.0后,不再支持terms直接查询以及terms下的注入minimum_match等参数,需要使用filter。
GET bank/account/_search
{
"query": {
"constant_score": {
"filter": {
"terms": {
"address": [
"avenue",
"street"
]
}
}
}
}
}
GET _search
{
"query": {
"range" : {
"age" : {
"gte" : 10,
"lte" : 20,
"boost" : 2.0
}
}
}
}
对于日期类型可以使用Date Math
"gte" : "now-1d/d",
"lt" : "now/d"
GET /_search
{
"query": {
"exists" : { "field" : "user" }
}
}
GET /_search
{ "query": {
"prefix" : { "state" : "p" }
}
}
GET /_search
{
"query": {
"wildcard" : { "city" : "*i*ey" }
}
}
详见官方文档
将在接下来的版本中删除,使用match queries with fuzziness替代。
匹配方式,是使用编辑距离Levenstein distance
GET /_search
{
"query": {
"type" : {
"value" : "account"
}
}
}
GET /_search
{
"query": {
"ids" : {
"type" : "account",
"values" : ["1", "4", "100"]
}
}
}